Marfeel creates a visual representation of how Googlebot sees your site, based on its structured data. When a user visits a page and triggers an event to Marfeel, the Editorial Crawler crawls the page and detects, extracts, and audits the structured data and extra metadata of the canonical url, such as the title, author, or section it belongs to.
This article lists issues you may find interesting
Missing metadata
There might be cases where extracted articles lack editorial information like the title or the author. Instead they show a plain url, such as https://domain.com/path/to/article in the example below:
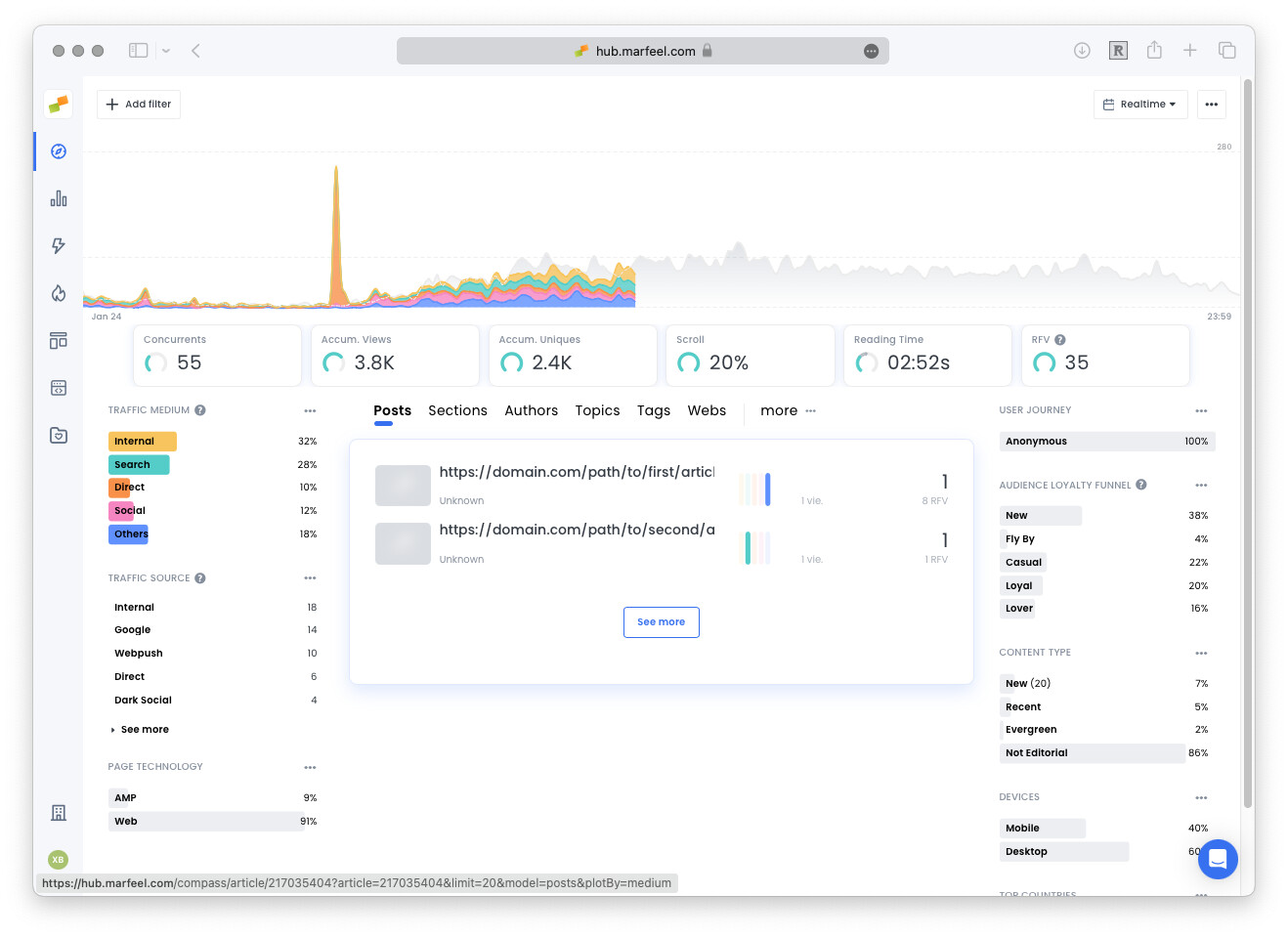
There are different situations that can cause the Marfeel Editorial Crawler to fail:
- WAF or Web Application Firewall. The Marfeel Editorial Crawler follows good citizen practices to throttle the number of concurrent requests per site, but if you have a WAF it might block the Marfeel crawlers. Follow these steps to whitelist them.
- URL with a non-existing canonical or without a title or an H1. Marfeel crawls all the information from the informed canonical url. If that fails, then the editorial information won’t be reported correctly.
- Yoast in combination with WPRocket cache plugin in Wordpress. Read more about some known issues with this set up.
- Detection of external sites. If you see domains that you don’t own, you’ll want to review your canonicals strategy.
- Using an article preview in your CMS may activate our SDK for traffic tracking. Keep in mind that if the link is not yet published, our web crawler cannot access or analyze the content. Essential plan users and above will benefit from our crawler’s persistent attempts to access the content, gradually reducing its frequency upon repeated failures. On Free plans, the crawler will halt attempts after 10 consecutive failures.
- Using JavaScript generated content or structured data. Despite Structure Data can be injected via Javascript, many studies like Onely or SearchEngineJournal) indicate that having JavaScript-generated content or structured data can lead to significant issues due to indexing delays by Google. This delay in indexing can hinder the visibility of the website’s pages on search engine results, potentially affecting overall traffic and ranking positions, but can also result in outdated news content being displayed to users. Therefore, it is advised to shift to server-side rendering content for news publishers to ensure timely delivery of current news content to their audience.
URLs from external hosts in your reports
There might be cases when using reporting that you see listed hosts and urls that you don’t operate.
There are a few known situations when this can happen:
- When your articles specify a canonical outside of your property
- When users use a reverse proxy
- Shared Google Tag Manager across sites
- Audits on referral pages
- Sites copying your content including Marfeel tracking
External canonical
By default, Marfeel attributes the traffic to the canonical URL informed on the page. If you are using syndicated content from a third-party site you might have to keep their canonical. On Marfeel all the traffic will be classified under the canonical url and domain, which might be different from your main domain.
If you want you can change the attribution using mrf:canonical
Reverse proxy
There are platforms and tools like translation pages that allow users to browse sites using a reverse proxy. The users consume your site content from sites like nproxy.org, anonymouspreview.org or anonymousviewer.org. These sites get a copy of your site and serve it to their readers. Marfeel JS tracks these sessions and respects the canonical they inform which, in lots of cases, is rewritten to the proxied domain.
Translation sites
Translation services like Google Translate work as reverse proxies (see above) serving translated versions from domains like https://www-site-com.translate.goog. These services serve the translated content along with the original JS, CSS and image resources. The translated page has a modified canonical. The Marfeel SDK tracks hits to the informed canonicals. If a page has no canonical defined, the Marfeel SDK will track the translated version as a separate URL and host.
Shared Google Tag Manager
In case Marfeel is implemented via Google Tag Manager make sure it’s only active on the desired sites. In multi property GTM instances you might deploy the pixel to multiple properties by mistake.
Domains copying your content
We have found situations where the publisher content is illegally copied / replicated including its entire markup and Javascript tracking. If Marfeel SDK is included in this replicated domains Marfeel will track the traffic and attribute it to the canonical URL that might be pointing or not to the original domain.
If that’s the case get in touch with the Marfeel Support and we’ll try to help providing a list of the URLs generating the hits.
Audits of pages without Marfeel pixel
The Marfeel Editorial crawler crawls any url with a real user hit. If it’s under the same domain, It also crawls the referral url to provide Previous pages information.
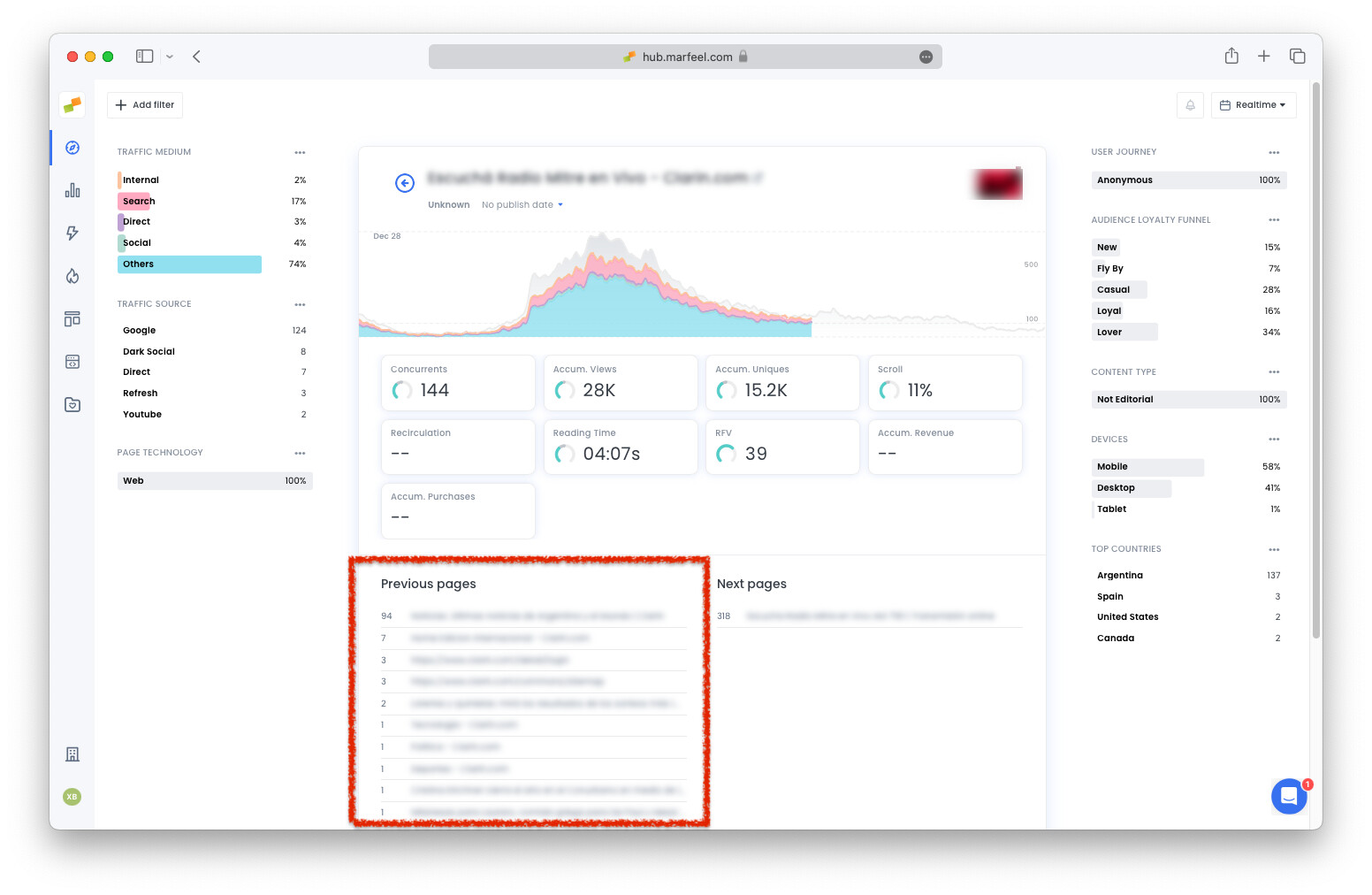
URLs discovered by the Editorial crawler are then processed by the Audits crawler.
There are publishers that add the Marfeel pixel only on certain folders or urls that live within the main domain of a different publication. i.e. The marfeel pixel is only present on domainA.com/folder/article but not on domainA.com. When a user coming from a page like domainA.com/any/referral recirculates to domainA.com/folder/article the Marfeel Editorial Crawler will crawl both the article and domainA.com/any/referral urls. If any audit triggers on the latter, Marfeel will report the issues too even if the pixel is not present on the referral pages.